Pipelines
Text classification
Zero-shot classification
Text generation
Text completion(mask filling)
Token classification
Question answering
Summarization
Translationhow pipeline run
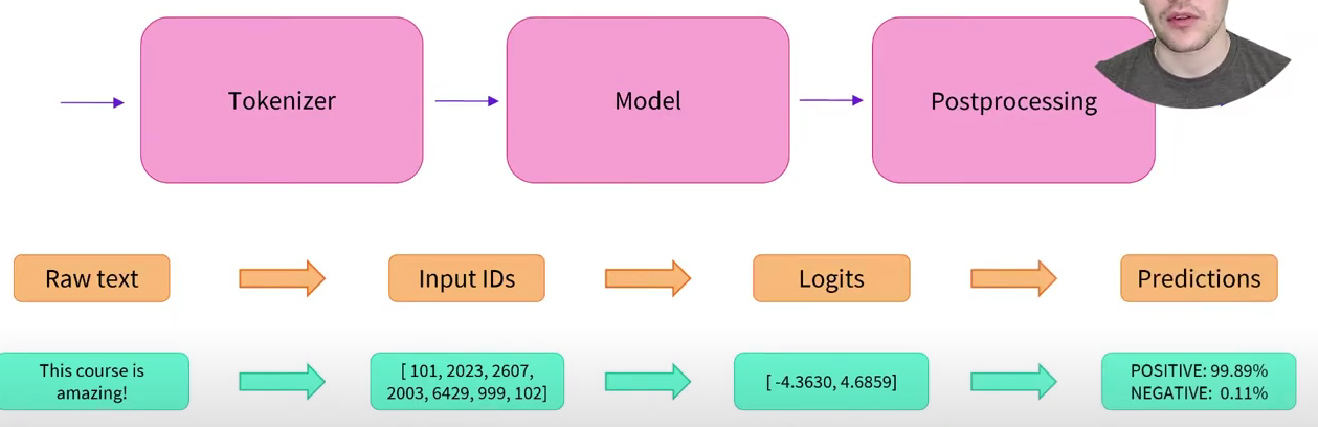
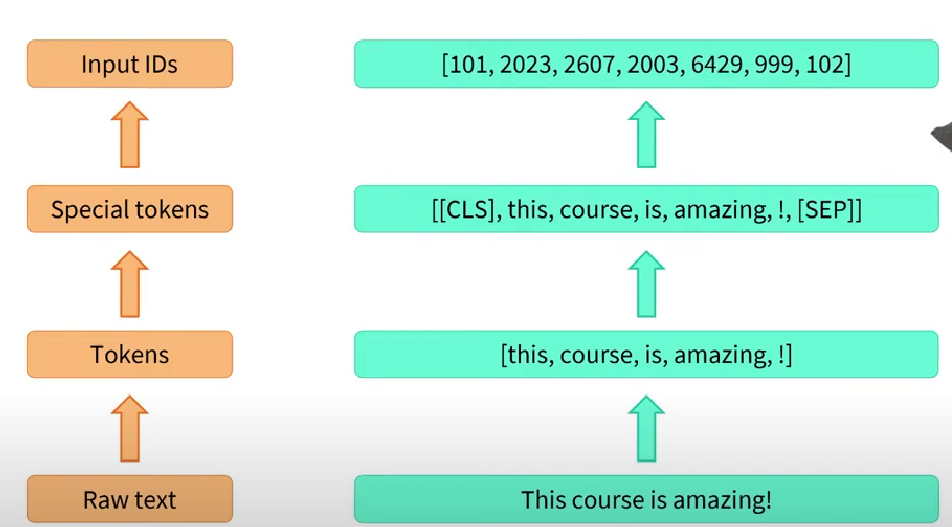
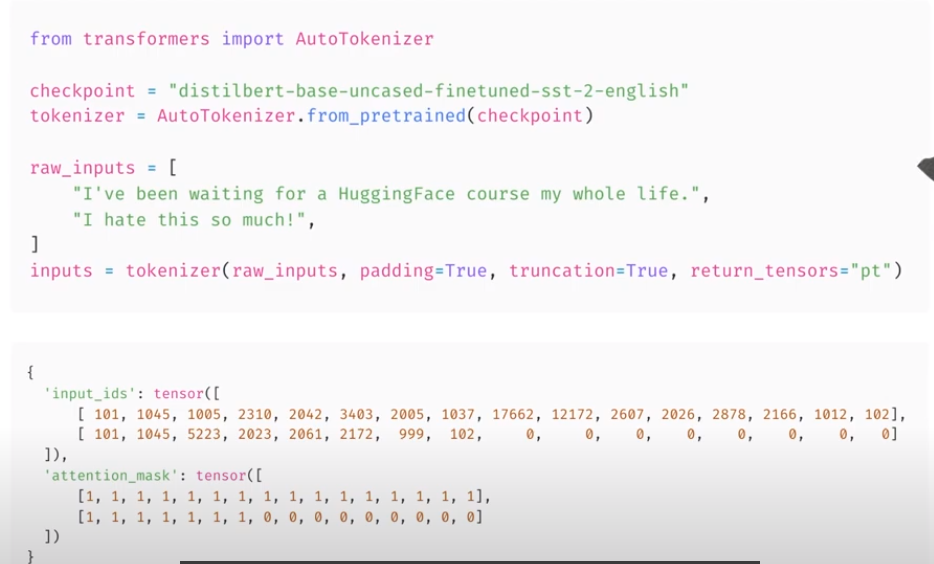
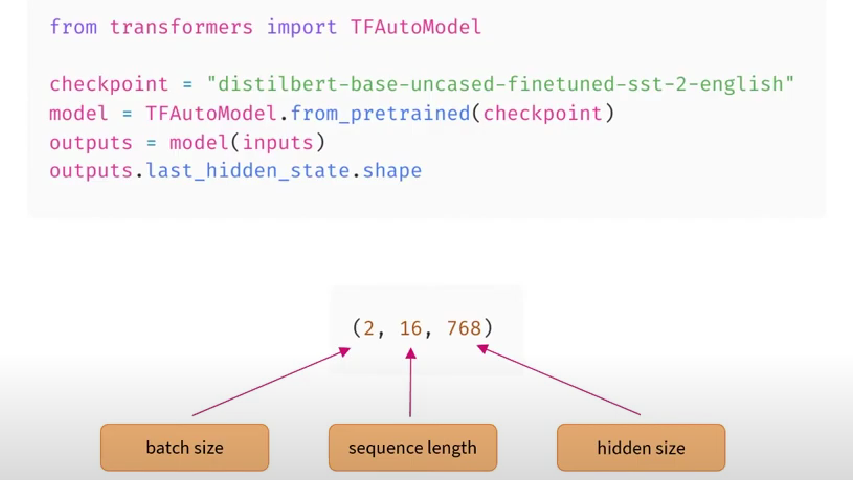

Carbon footprint
AutoNLPTransfer Learning
预训练是自我监督的,不需要人工注释
常见任务
词语预测
完形填空 [MASK]Architecture
encoder-decoder / sequence2sequence transformer
encoder 将文本进行数字化处理, 也叫做embedding(词嵌入)和feature tensor/vector(特征向量/张量),其输出的结果输入给解码器
self-attention
Bi-directional
decoder 通过编码器输入和其它输入生成预测,预测一个最大可能性的输出,并在未来迭代中重复使用该输出(autoregression 自回归, 输出值用于输入值)
Uni-directional
Auto-regressive
Masked self-attentionencoders
Definition
encoder擅长序列分类(analyze the sentiment of sequence)
Sentiment analysis 情感分析
BERT是仅有encoder的流行模型,基础bert维度为768
对传递的每一个单词均有一个向量(数组),每一个都是相关单词的数字表示,拥有一定的维度(特征数量),由不同技术的架构定义
每个单词会考虑周围的单词,即上下文;由768个value组成的向量构成了一个单词在其句子中的“含义”(自注意力机制)
Self-attention machanism(自注意力机制)
涉及单个序列中的不同位置/不同单词,以计算序列的表示。实现了一个单词的“含义”收到序列中其它单词的影响的效果
When to use
encoder可以用作独立模型——encoder在提取序列中的有价值的信息方面十分有效(BERT)
结果向量可以被额外的神经元处理以理解
在Masked Language Modeling(MLM, 掩码语言建模)中,双向信息十分重要。由于encoder的高序列理解特性,可以非常好的对这类任务进行预测decoders
Definition
decoder可以以较低的性能损失完成大多数decoder的任务
decoder与encoder不同的地方在于自注意力机制:
encoder可以访问双向上下文,而decoder不能。通过decoder输出的features只能访问左侧单词,而不能访问右侧的上下文(正确上下文)。
masked self-attention与self-attention不同。它使用额外的mask隐藏单词两侧的上下文(单纯的数字表示不受隐藏上下文中单词的影响)。
When to use
和编码器一样,decoder也可以用作独立模型(GPT-2 [max 1024 tokens], GPT Neo)。
由于其undirectional的特性, decoder在text generation方面更加擅长(NLG, Natural Language Generation).encoder-decoder(t5)
Definition
1. 将encoder的输出传递给decoder的输入,并为decoder添加一个序列(当提示解码器输出没有初始序列的输出时,给它一个指示序列开始的值(Start of sequence word))
2. 解码器解码,输出一个单词
3. 此时拥有feature vector && output word, 不再需要encoder
4. 自回归, 将new word添加到feature vector中, 直到生成了所有需要的值
*Start of sequence word 表示应该解码序列
Feature
encoder与decoder不耦合, 可以用于Sequence2Sequence, many2many, translation, summarization
encoder和decoder的部分权重互不影响
encoder和decoder的上下文可以不相同(Summarization)
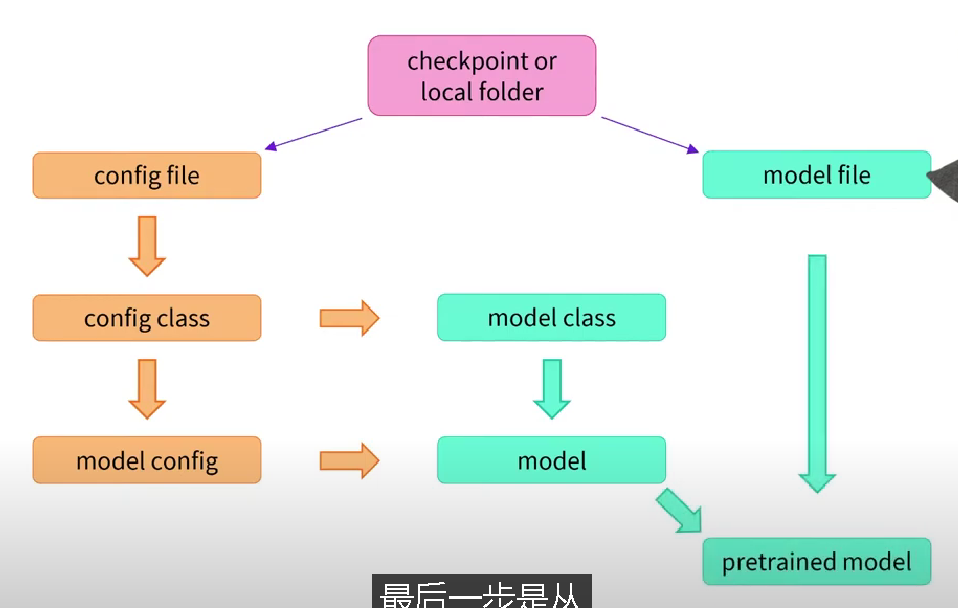
本身拥有一些模型,并且可以额外添加encoder && decoderInstantiate transform model
V




Tokenizers
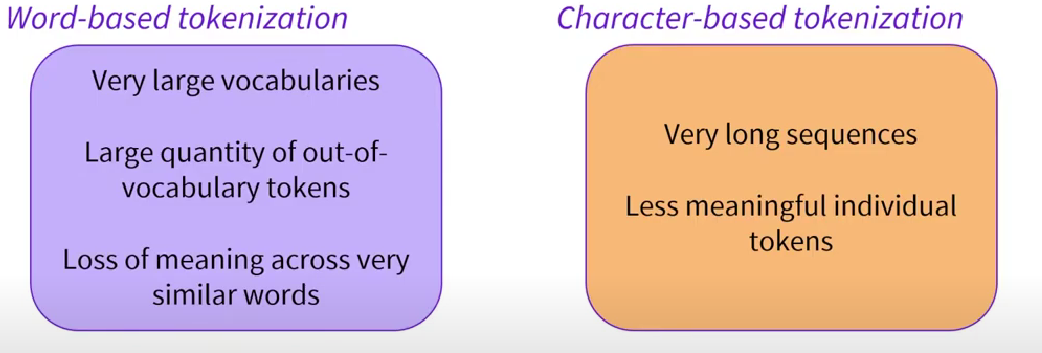
word-based 基于单词
巨大的词汇表(每一个词都对应一个大向量,词汇量越大,跟踪映射需要的权重就越大) 无法准确理解语义, 相近单词意义缺失 泛化能力弱,大量信息丢失character-based 基于字符
大量的词汇外标记(序列长度),影响信息携带的上下文大小 泛化能力相对于word-based更强 单个标记的信息密度低,信息量少subword-based 基于子词
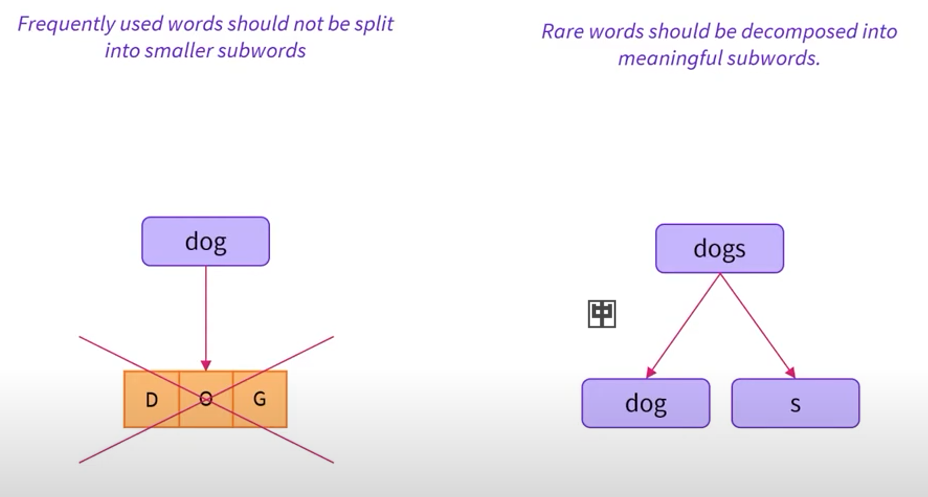
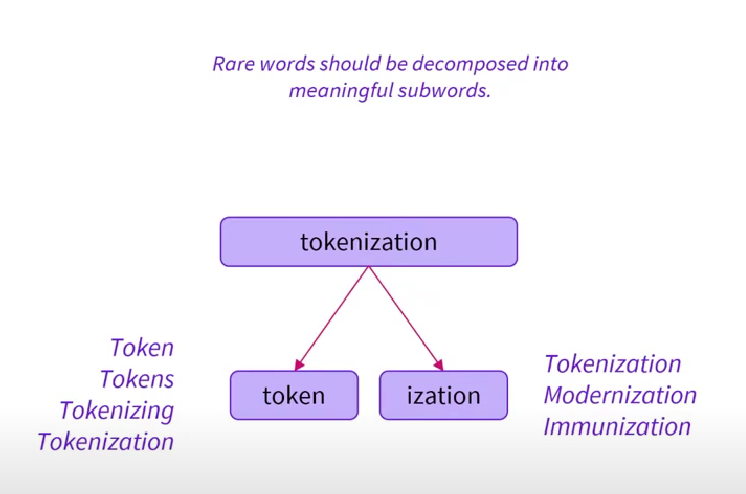
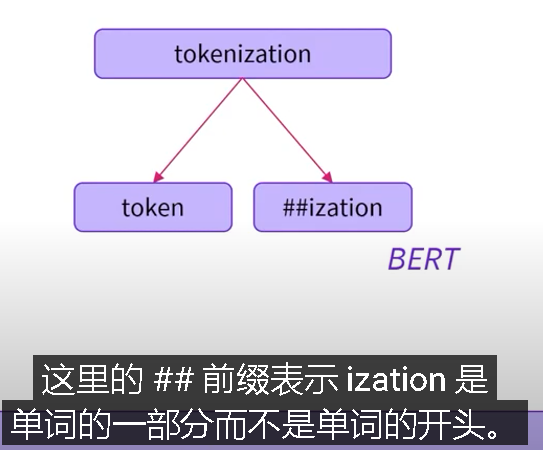
折中——频繁使用的单词,使用基于单词;低频单词拆分为子词 更强的泛化、理解能力