Node
基本概念
事件驱动的实质是什么?
事件循环 + 发布订阅为什么说Node可以用来构建高性能服务器? 通过Node构建的服务器为什么性能高?
1. Node的处理模式与传统的同步、并发模型不同,Node基于事件驱动,下属线程的性能开销较小:节省切换context的性能;无多线程创建和销毁带来的性能支出;Node的调用流程链? -> JS->Node核心模块-> c++内建模块 -> libuv下层调用
Node异步IO模型?-> 观察者 && 请求对象 && 线程池 && EventLoop
Linux nvm安装
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash同步与异步 && 阻塞与非阻塞
同步——对于APP,依然属于同步的范畴,无论是阻塞IO还是非阻塞IO,都需要等待数据返回
阻塞I/O与非阻塞I/O的原理->CPU时间片的利用问题
IO与OS的关系
IO与文件的关系
阻塞IO的问题->CPU资源浪费 (等待
阻塞IO在阻塞的过程中做了什么->通过kernel获取fileno并获取数据的整个流程,最后返回数据
事件循环中存在阻塞IO会发生什么?
后续IO无法更进,性能急剧下降,接近同步服务非阻塞IO的问题->轮询
非阻塞IO为什么是非阻塞->调用后直接返回,不返回数据;获取数据需要通过fileno再次查找
轮询的原理? -> 根据fileno查询
异步——
JS异步IO调用的流程? JS异步调用 -> 线程池——封装请求对象,进入IO pool -> 事件循环——调用IO,回调通知 (tick监听线程池中是否有执行完的请求
setTimeout / setInterval是如何将回调设置在固定的时间后执行的?
1. 定时器观察者内部的红黑树 2. 通过红黑树查找定时器对象->查找完毕 3. 检查是否过期:过期则创建事件并立即执行callback,否则继续监视 红黑树 - 用于解决二叉树搜索过程中,元素按顺序插入导致的极端情况:O(N)时间复杂度而产生的; - 有五条规则异步IO的核心是什么?
事件循环为什么会有process.nextTick呢?nextTick解决了什么问题?
node中,传统的timer基于事件循环,定时器观察者在事件循环中,充当一部分的运算; 事件循环本身效率很高,但不免会出现某一轮或者某几轮循环耗时过长,带来了可感知的timer延迟,这时的timer延迟可能导致很多问题; 结论: nextTick解决的是timer在某些情况下精度不够的问题nextTick为什么是在tick中最先执行的?-> nextTick() API 执行的流程是什么?
nextTick的调用机制和timer的基于观察者 && 红黑树查找的方式不同,前者使用队列的方式,只会将callback入队至nextTickQueue,在下一轮tick开始时取出 而timer需要通过查找、对比、执行等环节,nextTick的时间复杂度为O(1),而基于红黑树的时间复杂度为O(logN)为什么process.nextTick()的回调会比setImmediate()快呢?->nextTick()和setImmediate()的优先级问题
实质是事件循环的观察者优先级问题:process.nextTick()的观察者是idle观察者; setImmediate()的观察者是check观察者; 具体优先级: idle > IO > check nextTick的callback保存在数组中,每次执行都会同时执行和清空nextTickQueue的全部callback; immediate的callback保存在链表中,每次执行只执行其中一个回调;在EL中,每轮只执行一次immediate()为什么每轮只能执行一次immediate()?
控制每轮执行的时间以及性能开销
事件循环与异步IO
事件循环是一个死循环,在循环中不断处理事件;而异步IO是事件循环的一种,是包含与被包含的关系;另外的方法还有任务调度等。
在事件循环中,整个过程可以看为一条直线,大部分时间阻塞在等待事件;而等待的过程中并不消耗CPU资源,而是等待底层的epoll得到事件,一旦有事件完成,就会通知epoll,进入下一步。libuv会一路调用到Js层,调用Js的callback。
fs.readFile(filename, (err, content) => {
// 这里就是 callback
});libuv
libuv是跨平台的异步IO库,是Node事件循环的底层实现。
libuv 提供了事件循环、异步 I/O、定时器等功能,使 Node.js 能够在不同的操作系统上实现高性能的异步非阻塞操作。
tick
在Node的事件循环中,除了第一次启动由Node自身完成,其余都是通过kernel的epoll或者libuv的定时器等事件来触发执行。只有在触发后事件循环才会去处相应逻辑。其它的时间都阻塞在epoll的等待上。每次的触发称之为一个tick。
fs.readFile(filename, (err, content) => {
fs.writeFile(filename, content, err => {
// ...
});
setTimeout(() => {
// ...
}, 1000);
});代码的执行过程如下,每一个圆都是一个tick。
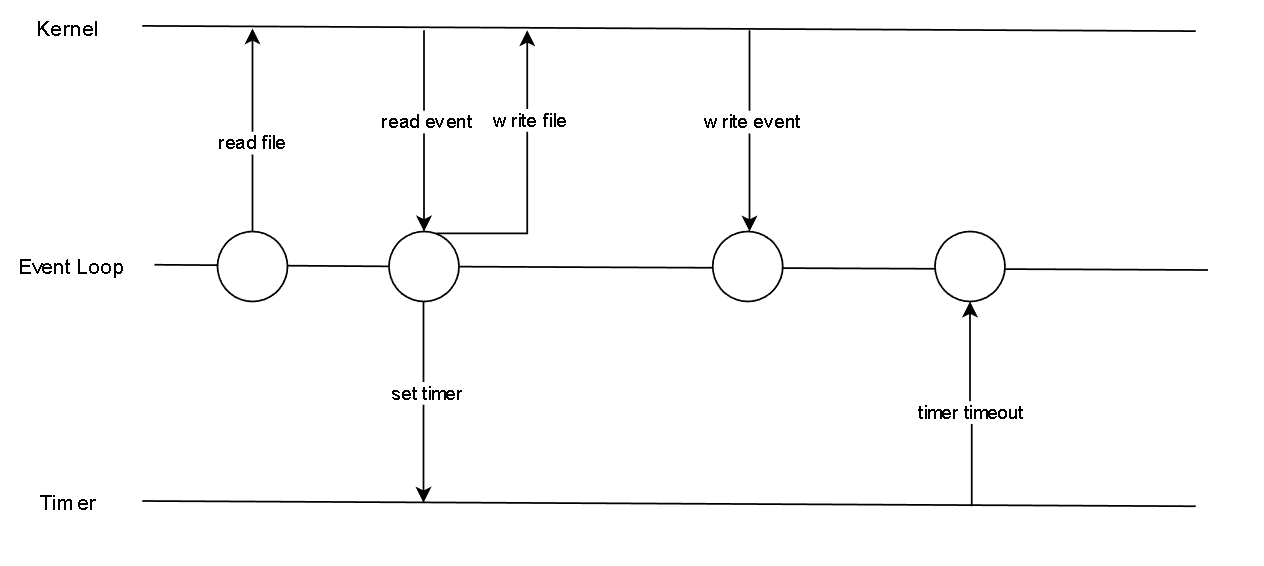
- 为什么会有tick?
- tick的作用是什么 / tick的过程做了什么? -> 在相应的阶段执行回调
- tick是如何知道要执行回调 -> 发布订阅 / 观察者
Js本身在V8的Browser runtime中有一套事件循环并发模型,而Node的事件循环机制由自己实现。
Node中借助libuv的uv_async_t,实现watchdog对timer的管控机制,本质上是IO的操作,具体内容交给kernel处理
Node主事件循环的每一个tick,都拥有内部的循环和对应watchdog的解析
主事件循环确保内部循环得以使其生命周期正常运转,会经常判断is_stopping
内循环通过uv_run,按顺序执行具体的代码:
1. timers:timeout hook
2. pending IO:少部分情况下,需要延迟IO,在下次tick开始时调用
3. 空转事件:若存在空转,直接continue;不等待IO;————————setImmediate()的机制:通过空转事件使其在tick中强行不等待IO
4. 准备事件:preprocess
5. poll 事件:大多数情况下,I/O 回调都会在poll IO后立即调用
6. check 复查事件:postprocess
7. 结束:close hook
时序相关:
timeout & interval
immediate
nextTick 其任务队列由node管理,通过固定位置设置实现;微任务队列由v8管理uv_async_t
在libuv中实现的用于线程安全地跨线程通信或在异步I/O完成后通知事件循环等场景。在Node中就是一个线程完成了一个任务后,通过uv_async_t通知主事件循环,也就是在下一个tick中主事件循环收到通知。
在vm模块中,使用了uv_async_t实现了对主事件循环本身的监视。vm在主事件循环中执行代码,而想要监视主事件循环,需要独立的线程管理,用于定时器超时时终止其运行。
在一个tick中,包含主线程和watchdog线程两个线程。
tick开始时会同时创建watch dogtimer、 watch dog event loop和主事件循环。主事件循环包括了Js死循环和watch dog解析。
watch dog timer在创建时启动,创建意味着tick开始。
watch dog timer到期意味着前半部分已经结束,tick进入了后半部分。
此时后半部分会解析watch dog并通过uv_async_t通知给watch dog event loop使其自我结束线程,主事件循环会等待线程结束的通知。
(为了线程安全,主循环也必须等待,不能直接kill掉watch dog线程)
通知到来后,后半部分也就结束,整个tick结束。Node事件循环源码
do {
if (env->is_stopping()) break;
uv_run(env->event_loop(), UV_RUN_DEFAULT);
if (env->is_stopping()) break;
platform->DrainTasks(isolate);
more = uv_loop_alive(env->event_loop());
if (more && !env->is_stopping()) continue;
if (EmitProcessBeforeExit(env).IsNothing())
break;
{
HandleScope handle_scope(isolate);
if (env->RunSnapshotSerializeCallback().IsEmpty()) {
break;
}
}
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env->event_loop());
} while (more == true && !env->is_stopping());内存管理
GC
堆内存是存储 JavaScript 对象的地方。V8 使用了一种称为分代垃圾回收的策略来管理堆内存。在这种策略中,堆内存被分为几个代,每个代有自己的内存分配器。具体前往FrontEnd-Other中的V8章节
Buffer
如何理解Buffer主要处理二进制数据?怎么理解这个“二”?
存储的元素为十六进制的二位数,以字符串为例,通过raw string进行编码,通过Buffer对象接收,转化为8位的二位数,而元素本身通过十六进制的方式存储和输出,
最后呈现的效果就是<Buffer a3 b4 a1 c9 83 21 ca ...>Node如何区别Buffer对象是大对象还是小对象?
以申请的Buffer对象的size:8K为基准
小于8K,即为小对象
大于8k,即为大对象讲一讲slab机制?为什么会有slab机制?
slab机制是动态内存管理机制,用于Node Buffer中进行高效的内存管理
slab是固定大小的,分配好了的内存区域,拥有full、partial和empty三种状态
通过new SlowBuffer(), 创建一个pool, pool中存放Buffer
以8K为基准,若其中的任意一个Buffer(pool chunk)超过了当前可用的范围,则会构建新的slab讲一讲slab的的预先申请和事后分配机制?这种机制解决了什么问题?
OS中:
预先申请机制:
预先申请机制指的是在系统启动时预先分配一定数量的内存作为缓存池,这些内存块被称为 SLAB 或 SLUB(SLAB allocator 或 SLUB allocator)。SLAB 是一种数据结构,用于保存同类型的内存块。每个 SLAB 包含了一定数量的同类型对象的内存块,这些对象可以被分配给需要它们的内核模块。
预先申请机制的主要目的是为了提高内存分配的效率。通过预先申请一定数量的内存块,避免了每次分配内存时都需要进行内存管理器的调用,从而降低了内存分配的开销。
事后分配机制:
事后分配机制指的是当内核模块需要内存时,从预先申请的缓存池中选择一个合适的 SLAB,并从中分配内存块给请求的模块。如果 SLAB 中没有足够的空闲内存块,系统会根据需要动态地增加新的 SLAB。
事后分配机制的主要目的是在系统运行时动态地管理内存,根据需求分配和释放内存,以确保系统的内存使用效率和性能。
这种预先申请和事后分配机制解决了内存碎片问题和内存分配效率问题。通过预先申请一定数量的内存块,可以避免内存碎片的产生,提高内存的利用率;而通过事后分配机制,可以动态地管理内存,根据需求分配和释放内存,提高了内存分配的效率和性能。
---
Node中:
SLAB 分配器主要用于管理 JavaScript 对象的内存分配和释放。Node.js 中的 V8 引擎采用了一种名为 "Orinoco" 的 SLAB 分配器。在这个分配器中,预先申请和事后分配机制同样是内存管理的重要组成部分。
预先申请机制:
在 Node.js 启动时,V8 引擎会预先申请一定数量的内存作为堆内存。
在预先申请的阶段,V8 引擎会为新生代和老生代分配一定数量的内存空间,并将其划分为不同大小的内存块。
事后分配机制:
当 JavaScript 代码执行时,需要分配新的对象或变量时,V8 引擎会从预先申请的堆内存中选择一个合适大小的内存块,并将其分配给新对象或变量。
如果没有足够的空闲内存块可用,V8 引擎会触发垃圾回收机制来释放一些不再使用的内存,然后再进行内存分配。
提高内存分配和释放效率,提高应用程序的性能和稳定性
减少内存碎片,避免频繁的内存分配和释放操作引申知识
概念
文件描述符
文件描述符(File Descriptor)是一种用于标识和访问已打开文件的抽象概念。文件描述符是一个非负整数,它是进程中打开文件的索引或句柄。每个进程在其打开的文件、套接字、管道等资源上都有一个唯一的文件描述符。
- 非负整数:文件描述符是一个非负整数。通常,0、1和2分别代表标准输入、标准输出和标准错误。
- 进程级别:文件描述符是进程级别的,每个进程都有独立的文件描述符表。这意味着一个进程可以打开相同的文件,但它们的文件描述符是不同的。
- 通过系统调用进行创建和操作:文件描述符是通过系统调用(如
open、socket、pipe等)返回的。系统调用返回的文件描述符可以用于读取、写入、关闭等文件操作。 - 标准文件描述符:在UNIX系统中,通常有三个标准文件描述符:
- 0(
STDIN_FILENO):标准输入 - 1(
STDOUT_FILENO):标准输出 - 2(
STDERR_FILENO):标准错误
- 0(
- 套接字和管道:文件描述符不仅用于表示打开的文件,还用于表示套接字、管道等I/O资源。这使得在UNIX系统中,文件描述符成为一种通用的I/O抽象。
I/O 多路复用
在不同系统上的多路复用:Linux epoll, Mac kqueue, windows IOCP(网络请求: c-ares)
- 平台差异:
epoll是Linux特有的,而kqueue是BSD系列系统中的特有机制。IOCP则是Windows特有的异步I/O机制。 - 事件驱动模型:
epoll和kqueue都采用事件驱动的模型,而IOCP则是Windows的异步I/O机制,使用完成端口(Completion Port)来管理异步操作的完成。 - 接口和用法:由于是在不同的操作系统上实现,它们的接口和用法有所不同。程序需要根据目标操作系统选择相应的机制。
POSIX规范
POSIX(Portable Operating System Interface)规范用于定义操作系统接口相关规范。
API
vm
vm(Virtual Machine),提供代码运行的沙盒隔离环境,使得代码能在指定context中运行,不会影响到主程序的状态。
vm.createContext([sandbox]):
用于创建一个新的上下文对象,可选参数 sandbox 是一个对象,将在新的上下文中成为全局对象。
vm.runInContext(code, contextifiedSandbox[, options]):
在指定的上下文中执行 JavaScript 代码。
code 是要执行的 JavaScript 代码。
contextifiedSandbox 是一个通过 vm.createContext 创建的上下文对象。
options 是一个可选的选项对象,可以包括 filename(指定文件名)和 lineOffset(指定代码的行偏移量)等属性。
vm.runInNewContext(code[, sandbox][, options]):
在一个新的上下文中执行 JavaScript 代码。
code 是要执行的 JavaScript 代码。
sandbox 是一个可选的对象,将在新的上下文中成为全局对象。
options 是一个可选的选项对象,可以包括 filename(指定文件名)和 lineOffset(指定代码的行偏移量)等属性。
vm.runInThisContext(code[, options]):
在当前上下文中执行 JavaScript 代码。
code 是要执行的 JavaScript 代码。
options 是一个可选的选项对象,可以包括 filename(指定文件名)和 lineOffset(指定代码的行偏移量)等属性。